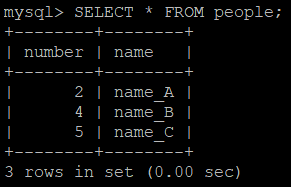
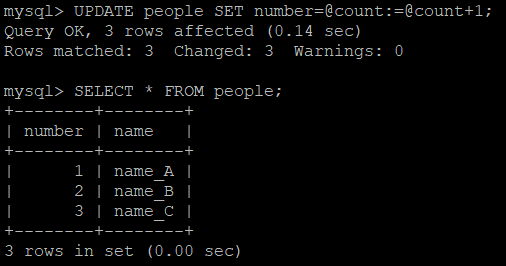
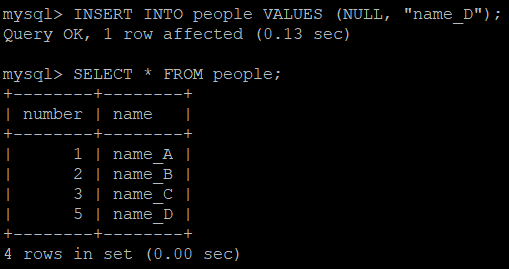
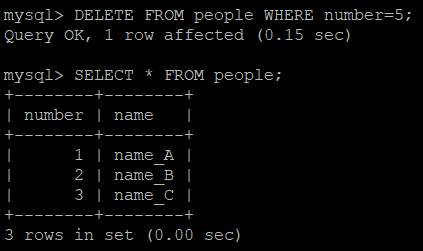
MySQL Blocking Query
Version 5.7
select blocking.trx_mysql_thread_id as blocking_processlist_id
,max(proc.USER) as blocking_user
,max(proc.HOST) as blocking_host
,max(proc.DB) as blocking_db
,max(ifnull(blocking.trx_query, 'Null')) as blocking_query
,max(TIMESTAMPDIFF(second, blocking.trx_started, now())) as blocking_started_sec
,max(ifnull(blocking.trx_started, 'Null')) as blocking_started_time
,max(blocking.trx_state) as blocking_state
,'Null' as blocking_command
,max(concat(blocking.trx_id, ' (', ifnull(waiting.blocking_lock_id, 'Null'), ')')) as trx_id
,max(ifnull(lock_info.lock_mode, 'Null')) as lock_mode
,max(ifnull(lock_info.lock_type, 'lock')) as lock_type
,if(max(waiting_info.trx_started is not null)
,concat('\nlock waiting into : ', count(*)
,substring(group_concat('\n\t'
,'waiting ', now() - waiting_info.trx_started, '(sec) : '
,'query -> ', waiting_info.trx_query
order by waiting_info.trx_started), 1, 1000))
,'\nlock waiting into : Null') as trx_info
from information_schema.INNODB_TRX blocking
left join information_schema.INNODB_LOCK_WAITS waiting on waiting.blocking_trx_id = blocking.trx_id
left join information_schema.INNODB_TRX waiting_info on waiting_info.trx_id = waiting.requesting_trx_id
left join information_schema.INNODB_LOCKS lock_info on lock_info.lock_trx_id = blocking.trx_id
inner join information_schema.processlist proc on proc.id = blocking.trx_mysql_thread_id
where blocking.trx_state = 'RUNNING'
and blocking.trx_requested_lock_id is null
and blocking.trx_wait_started is null
group by blocking.trx_mysql_thread_id ;
MySQL Status Check Query
Version 5.7 & 8.0
select concat('LongQuery', '::', count(*)) as current_value
from information_schema.processlist proc
where proc.command not in ('sleep', 'daemon', 'binlog dump', 'killed')
and proc.id <> connection_id()
and proc.time > 10
union all
select concat('LongTransaction', '::', count(*)) as current_value
from information_schema.innodb_trx trx
where TIMEDIFF(now(), trx.trx_started) > '00:01:00'
union all
select concat('MetaLock', '::', count(*)) as current_value
from performance_schema.metadata_locks ml
where ml.lock_status = 'PENDING'
union all
select concat('LockWait', '::', count(*)) as current_value
from information_schema.INNODB_TRX trx
where trx.trx_state = 'LOCK WAIT'
and trx.trx_wait_started <= date_sub(now(), interval 3 second) ;
MySQL Long Query
Version 5.7 & 8.0
select proc.time, proc.command, proc.id
, proc.user, proc.host, proc.db, proc.info
from information_schema.processlist proc
where proc.command not in ('sleep', 'daemon', 'binlog dump', 'killed')
and proc.id <> connection_id()
and proc.time > 10
order by proc.time desc ;
MySQL Long Transaction Query
Version 5.7 & 8.0
select trx_mysql_thread_id as 'id'
, proc.user
, proc.host
, proc.command
, trx.trx_state
, concat(trx_started, '') as 'start_time'
, concat(TIMEDIFF(now(), trx_started), '') as 'diff_time'
, ifnull(trx_query, '.......') as 'query_info'
, ( select ifnull(esc.SQL_TEXT, '.......')
from performance_schema.threads thread
, performance_schema.events_statements_current esc
where thread.processlist_id = trx.trx_mysql_thread_id
and esc.thread_id = thread.thread_id) as 'query_info2'
from information_schema.innodb_trx trx
,information_schema.processlist proc
where proc.id = trx.trx_mysql_thread_id
and trx.trx_query is null
and TIMEDIFF(now(), trx.trx_started) > '00:01:00'
order by trx_started ;
MySQL Meta Lock Query
Version 5.7 & 8.0
select th.thread_id as 'blocking_thread_id'
, th.processlist_id as 'blocking_id'
, th.processlist_user as 'blocking_user'
, th.processlist_host as 'blocking_host'
, th.processlist_db as 'blocking_db'
, th.processlist_command as 'blocking_command'
, th.processlist_time as 'blocking_time'
, ifnull(th.processlist_state, '---') as 'blocking_state'
, ifnull(th.processlist_info, ifnull((select esc.sql_text
from performance_schema.events_statements_current esc
where esc.thread_id = th.thread_id), '---')) as 'blocking_query'
, (select group_concat(concat('(id : ', waiting.processlist_id, ', waiting : ', waiting.processlist_time, ' sec) -> ', processlist_info)
order by waiting.processlist_time desc)
from performance_schema.threads waiting
where waiting.processlist_state = 'Waiting for table metadata lock') as 'waiting_query'
from (select granted.owner_thread_id
,count(*) as cnt
from performance_schema.metadata_locks pending
,performance_schema.metadata_locks granted
where pending.lock_status = 'PENDING'
and granted.object_type = pending.object_type
and granted.object_schema = pending.object_schema
and granted.object_name = pending.object_name
and granted.owner_thread_id != pending.owner_thread_id
and granted.lock_status = 'GRANTED'
group by granted.owner_thread_id
order by 2 desc
limit 1) as metalock_parent
,performance_schema.threads th
where th.thread_id = metalock_parent.owner_thread_id
and th.processlist_time >= 3 ;
MySQL Lock Wait Query
Version 8.0
select TIMESTAMPDIFF(second, trx_waiting.trx_started, now()) as 'waiting_started_sec'
, concat(trx_waiting.trx_started, '') as 'waiting_started_time'
, trx_waiting.trx_state as 'waiting_state'
, waiting_thread.processlist_command as 'waiting_command'
, waiting_thread.processlist_id as 'waiting_processlist_id'
, waiting_thread.processlist_user as 'waiting_user'
, waiting_thread.processlist_host as 'waiting_host'
, waiting_thread.processlist_db as 'waiting_db'
, waiting_thread.processlist_info as 'waiting_query'
, TIMESTAMPDIFF(second, blocking_thread_time.trx_started, now()) as 'blocking_started_sec'
, concat(blocking_thread_time.trx_started, '') as 'blocking_started_time'
, blocking_thread_time.trx_state as 'blocking_state'
, blocking_thread.processlist_command as 'blocking_command'
, blocking_thread.processlist_id as 'blocking_processlist_id'
, blocking_thread.processlist_user as 'blocking_user'
, blocking_thread.processlist_host as 'blocking_host'
, blocking_thread.processlist_db as 'blocking_db'
, ifnull(blocking_thread.processlist_info
, (select esc.SQL_TEXT
from performance_schema.events_statements_current esc
where esc.thread_id = blocking_thread.thread_id)) as 'blocking_query'
from information_schema.innodb_trx trx_waiting
,performance_schema.data_lock_waits dlw
,performance_schema.threads waiting_thread
,performance_schema.threads blocking_thread
,information_schema.innodb_trx blocking_thread_time
-- performance_schema.events_statements_current
where trx_waiting.trx_state = 'LOCK WAIT'
and trx_waiting.trx_wait_started <= date_sub(now(), interval 3 second)
and cast(dlw.requesting_engine_transaction_id as char charset utf8mb4) = trx_waiting.trx_id
and waiting_thread.thread_id = cast(dlw.requesting_thread_id as char charset utf8mb4)
and blocking_thread.thread_id = cast(dlw.blocking_thread_id as char charset utf8mb4)
and blocking_thread_time.trx_id = cast(dlw.BLOCKING_ENGINE_TRANSACTION_ID as char charset utf8mb4) ;