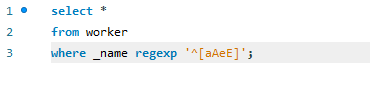
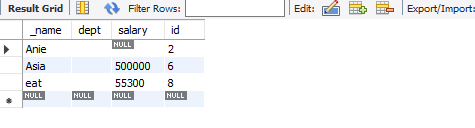
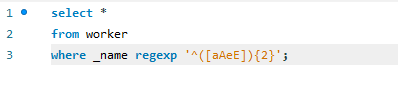
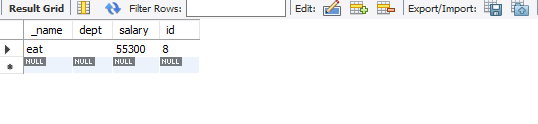
MySQL - Access denied; you need (at least one of) the SYSTEM_USER privilege(s) for this operation
DB Troubleshooting/MySQL 2022. 4. 5. 23:43
현상
권한 부여 및 DB 복원시 실행이 되지 않고 에러 발생
원인
실행 계정에 SYSTEM_USER 권한 부재
복원하는 DB의 procedure가 있는경우, definer로 설정되지 않은 계정으로 복원 시도
에러 문구
ERROR 1227 (42000) at line 375: Access denied; you need (at least one of) the SYSTEM_USER privilege(s) for this operation
해결
복원하는 DB의 procedure definer 이슈인 경우, definer로 설정된 계정으로 DB 복원(procedure 생성) 진행
| // system_user 권한 추가 형태 [linux]# mysql -u admin_user -p -P 3306 TestDB < TestDB.sql ERROR 1227 (42000) at line 375: Access denied; you need (at least one of) the SYSTEM_USER privilege(s) for this operation mysql> show grants for 'admin_user'@'localhost'; +--------------------------------------------------------------------------------------------- | Grants for admin_user@localhost +--------------------------------------------------------------------------------------------- | GRANT ALL PRIVILEGES ON *.* TO `admin_user`@`localhost` WITH GRANT OPTION +--------------------------------------------------------------------------------------------- 1 rows in set (0.00 sec) mysql> grant system_user on *.* to 'admin_user'@'localhost'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> show grants for 'admin_user'@'localhost'; +--------------------------------------------------------------------------------------------- | Grants for admin_user@localhost +--------------------------------------------------------------------------------------------- | GRANT ALL PRIVILEGES ON *.* TO `admin_user`@`localhost` WITH GRANT OPTION | GRANT SYSTEM_USER ON *.* TO `admin_user`@`localhost` +--------------------------------------------------------------------------------------------- 2 rows in set (0.00 sec) [linux]# mysql -u admin_user -p -P 3306 TestDB < TestDB.sql [linux]# |
참고
https://dev.mysql.com/blog-archive/the-system_user-dynamic-privilege/
'DB Troubleshooting > MySQL' 카테고리의 다른 글
| MySQL 접속 에러 error while loading shared libraries: libssl.so.1.1 / libcrypto.so.1.1 (0) | 2022.08.26 |
|---|---|
| mysql에서 잘못된 numa 사용으로 swap 발생하여 성능 지연 발생 (0) | 2022.08.02 |
| MySQL db down - btrfs filesystem full (0) | 2022.04.04 |
| MySQL 고비용 쿼리로 인한 Memory 고갈 후 swap 사용으로 지연 처리 (0) | 2022.03.17 |
| MySQL max_allowed_packet 설정 오류로 Replication Error (0) | 2022.03.17 |