SQL Server Agent 서비스 제어는 SQL Server Agent Roles 권한이 부여되어 있거나 또는 sysadmin role 이 부여되어 있어야 합니다. test_srv 계정은 SQL Sever Agent Roles 또는 sysadmin role 이 없습니다.
해결방법
방법1. SSMS - Security - Logins - test_srv - User Mapping - msdb - SQLAgentUserRole 부여(필요에 따라 SQLAgentReaderRole, SQLAgentOperatorRole 부여 가능) 단, 운영체제 외부 리소스를 사용하기 위해서는 별도의 Credentials, SQL Server Proxy Accounts 를 설정할 수 있음.
test_srv 계정에 view database 권한 필요
USE [master] GO
CREATE USER [test_srv] FOR LOGIN [test_srv]
USE [msdb] GO
CREATE USER [test_srv] FOR LOGIN [test_srv]
ALTER ROLE [SQLAgentUserRole] ADD MEMBER [test_srv]
만약 개체 존재 여부를 먼저 체크 하는 로직을 실행 한다면 아래 권한 추가
USE [msdb] GO GRANT SELECT ON sysjobs TO [test_srv] GRANT SELECT ON sysjobsteps TO [test_srv]
개체의 정의가 변경된다고 해서 이 개체를 참조하는 (스키마 바인딩 되지 않은) SP, UDF, VIEW의 메타데이터가 자동으로 갱신되지는 않습니다.
해결
--SQL Server 2000 참조한 개체는 Alter를 이용해서 다시 컴파일되어야 합니다. VIEW의 경우 sp_refreshview가 존재했지만, 다른 개체는 일일히 수작업을 해야 했었죠.
--SQL Server 2005 SQL Server 2005 SP2에서 sp_refreshsqlmodule 이 처음으로 소개되었습니다. 이 system sp를 이용하면 변경된 개체를 참조하는 SP, UDF, VIEW에 대해서 한번에 변경된 메타데이터를 갱신해 줍니다. 여전히 sp_refreshview도 사용 가능합니다.
실행 예) EXEC sys.sp_refreshsqlmodule 'dbo.to_upper';
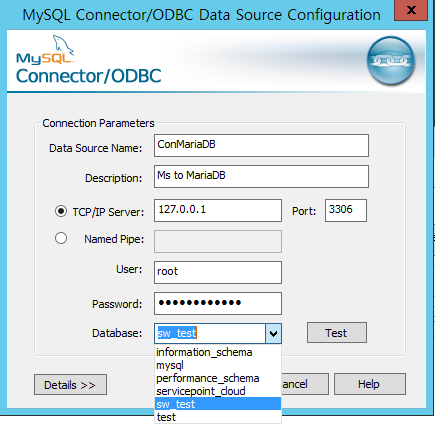
1. MySQL Connector ODBC 설치 2. ODBC 데이터 원본(64) 실행 3. 시스템 DSN에 등록 4. 시스템 DSN에 등록한 이름으로 MSSQL LinkedServer 생성 5. 접속 중 MSDASQL의 스키마 또는 카탈로그 에러시, 연결되 서버 -> 공급자 -> MSDASQL -> 속성 옵션 수정 6. 오픈 쿼리로 실행 ( select * from openquery ( 'DSN이름', 'select * from tbl_a')
adhoc 쿼리를 과도하게 호출 시 cached plan이 저장 가능한 공간을 초과 할 수 있음.
아래의 경우 1회만 사용되는 plan이 대부분인 케이스
1회만 사용되는 plan을 sp_executesql 형태로 변경하거나 동일 plan을 사용하도록 유도가 필요함
-- 모든 cached plan을 조회
select objtype, count(*) as cnt, sum(convert(bigint, size_in_bytes))/(1024*1024) as size_mb
from sys.dm_exec_cached_plans
--where usecounts = 1
group by objtype
order by cnt desc
/**
objtype cnt size_mb
Adhoc 156329 6906 <--
Prepared 3708 967
View 1285 181
Proc 215 253
**/
-- cached plan 사용 횟수가 1회 경우만 조회
select objtype, count(*) as cnt, sum(convert(bigint, size_in_bytes))/(1024*1024) as size_mb
from sys.dm_exec_cached_plans
where usecounts = 1
group by objtype
order by cnt desc
/**
objtype cnt size_mb
Adhoc 153763 1889 <--
Prepared 3145 242
Proc 41 19
**/
query_hash 통한 이슈 query 확인
이슈 query 확인 후 수정
-- 실행 count가 1인 경우만 조회
select query_hash, count(*) as cnt
from sys.dm_exec_query_stats
where execution_count = 1
group by query_hash
order by cnt desc
/**
query_hash cnt
0xD1CC06V33C082806 135420 <--- 확인
0x3129830A6071HND2 2108
0x30E30C19A239CX39 218
0x690CY4EC5110G475 218
~
**/
-- 이슈 query text 확인
select top 100 st.text
from sys.dm_exec_query_stats qs
cross apply sys.dm_exec_sql_text (qs.sql_handle) as st
where qs.query_hash = 0xD1CC06V33C082806
/**
USE master INSERT INTO *******************
USE master INSERT INTO *******************
**/
USE AdventureWorks2012 ;
GO
EXEC sp_configure 'show advanced options', 1;
GO
RECONFIGURE ;
GO
-- 정보 확인
EXEC sp_configure 'max worker threads'
-- max worker threads를 900으로 변경
EXEC sp_configure 'max worker threads', 900 ;
GO
RECONFIGURE;
GO
CPU Core별 사용 가능 카운트
CPU 수
32비트 컴퓨터(최대 SQL Server 2014(12.x))
64비트 컴퓨터(최대 SQL Server 2016(13.x) SP1)
64비트 컴퓨터(SQL Server 2016(13.x) SP2 및 SQL Server 2017(14.x)부터)
2. services.msc에 Remote Registry가 시작되었는지 체크 3. unlodctr 와 lodctr 을 이용해서 SQL 관련 카운터를 다시 등록할것
1) cmd(Administrator권한으로)
2) SQL SERVER의 binn폴더로 이동
3)unlodctr을 이용해서 SQL counters를 unload한다.
e.g. unlodctr MSSQLSERVER (for default instance)
e.g. unlodctr SQLSERVERAGENT (for default SQL Agent)
e.g. unlodctr MSSQL$TEST (for named instance)
e.g. unlodctr SQLAGENT$TEST (for SQL agent)
4)lodctr을 이용해서 SQL counters를 다시 등록한다.
e.g. lodctr perf-MSSQLSERVERsqlctr.ini (for default instance)
e.g. lodctr perf-SQLSERVERAGENTsqlagtctr.ini (for default SQL Agent)
e.g. lodctr perf-MSSQL$TESTsqlctr.ini (for named instance)
e.g. lodctr perf-SQLAGENT$TESTsqlagtctr.ini (for SQL Agent)
5)Remote Registry service를 다시 시작한다.
net stop "Remote Registry"
net start "Remote Registry"
6)필요할 경우 WMI와 WinPrivSE.exe 싱크를 다시 맞춘다.
e.g. winmgmt /resyncperfctr "5660"
cf)5660은 WinPrivSE.exe 의 pid
4. performance counter를 재등록 한다.
lodctr /R --> 모든
주의!!! 모든 performance counter registry 세팅을 재등록하게 된다.
권장 버전 : SQLServer 2017 이상( wait type 및 temp 경합 확인 가능 )
SSMS : Management Studio 버전 16 이상
구성
SET QUERY_STORE = ON (OPERATION_MODE = READ_WRITE);
GUI
쿼리 저장소를 사용하도록 설정한 후 개체 탐색기 창의 데이터베이스 부분을 새로 고쳐쿼리 저장소섹션을 추가
재발된 쿼리를 선택하여에서재발된 쿼리 SQL Server Management Studio창을 엽니다. 재발된 쿼리 창에는 쿼리 저장소의 쿼리 및 계획이 표시됩니다. 맨 위의 드롭다운 상자를 사용하여 다양한 기준으로 쿼리를 필터링합니다.기간(밀리초)(기본값), CPU 시간(밀리초), 논리적 읽기(KB), 논리적 쓰기(KB), 물리적 읽기(KB), CLR 시간(ms), DOP, 메모리 사용량(KB), 행 수, 사용된 메모리(KB), 사용된 임시 DB 메모리(KB), 대기 시간(밀리초).
계획을 선택하면 그래픽 쿼리 계획이 표시됩니다. 단추를 사용하여 원본 쿼리를 보고, 쿼리 계획을 강제로 적용 및 적용 해제하고, 그리드 형식과 차트 형식 간에 전환하고, 선택한 계획을 비교하고(두 개 이상 선택한 경우), 디스플레이를 새로 고칠 수 있습니다.
SELECT q.query_id, qt.query_text_id, qt.query_sql_text,
SUM(rs.count_executions) AS total_execution_count
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
GROUP BY q.query_id, qt.query_text_id, qt.query_sql_text
ORDER BY total_execution_count DESC;
지난1시간 내에 평균 실행 시간이 가장 긴 쿼리 수는 몇 개입니까?
SELECT TOP 10 rs.avg_duration, qt.query_sql_text, q.query_id,
qt.query_text_id, p.plan_id, GETUTCDATE() AS CurrentUTCTime,
rs.last_execution_time
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
WHERE rs.last_execution_time > DATEADD(hour, -1, GETUTCDATE())
ORDER BY rs.avg_duration DESC;
지난 24시간 동안 평균 물리적 I/O 읽기가 가장 큰 쿼리 수 및 해당하는 평균 행 수 및 실행 수는 몇 개입니까?
SELECT TOP 10 rs.avg_physical_io_reads, qt.query_sql_text,
q.query_id, qt.query_text_id, p.plan_id, rs.runtime_stats_id,
rsi.start_time, rsi.end_time, rs.avg_rowcount, rs.count_executions
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
JOIN sys.query_store_runtime_stats_interval AS rsi
ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rsi.start_time >= DATEADD(hour, -24, GETUTCDATE())
ORDER BY rs.avg_physical_io_reads DESC;
여러 계획을 사용하는 쿼리는 무엇입니까?
WITH Query_MultPlans
AS
(
SELECT COUNT(*) AS cnt, q.query_id
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON p.query_id = q.query_id
GROUP BY q.query_id
HAVING COUNT(distinct plan_id) > 1
)
SELECT q.query_id, object_name(object_id) AS ContainingObject,
query_sql_text, plan_id, p.query_plan AS plan_xml,
p.last_compile_start_time, p.last_execution_time
FROM Query_MultPlans AS qm
JOIN sys.query_store_query AS q
ON qm.query_id = q.query_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_query_text qt
ON qt.query_text_id = q.query_text_id
ORDER BY query_id, plan_id;
최근에 성능이 저하된 쿼리(다른 시점과 비교)는 무엇입니까?
SELECT
qt.query_sql_text,
q.query_id,
qt.query_text_id,
rs1.runtime_stats_id AS runtime_stats_id_1,
rsi1.start_time AS interval_1,
p1.plan_id AS plan_1,
rs1.avg_duration AS avg_duration_1,
rs2.avg_duration AS avg_duration_2,
p2.plan_id AS plan_2,
rsi2.start_time AS interval_2,
rs2.runtime_stats_id AS runtime_stats_id_2
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p1
ON q.query_id = p1.query_id
JOIN sys.query_store_runtime_stats AS rs1
ON p1.plan_id = rs1.plan_id
JOIN sys.query_store_runtime_stats_interval AS rsi1
ON rsi1.runtime_stats_interval_id = rs1.runtime_stats_interval_id
JOIN sys.query_store_plan AS p2
ON q.query_id = p2.query_id
JOIN sys.query_store_runtime_stats AS rs2
ON p2.plan_id = rs2.plan_id
JOIN sys.query_store_runtime_stats_interval AS rsi2
ON rsi2.runtime_stats_interval_id = rs2.runtime_stats_interval_id
WHERE rsi1.start_time > DATEADD(hour, -48, GETUTCDATE())
AND rsi2.start_time > rsi1.start_time
AND p1.plan_id <> p2.plan_id
AND rs2.avg_duration > 2*rs1.avg_duration
ORDER BY q.query_id, rsi1.start_time, rsi2.start_time;
가장 오래 대기 중인 쿼리는 무엇인가요?
SELECT TOP 10
qt.query_text_id,
q.query_id,
p.plan_id,
sum(total_query_wait_time_ms) AS sum_total_wait_ms
FROM sys.query_store_wait_stats ws
JOIN sys.query_store_plan p ON ws.plan_id = p.plan_id
JOIN sys.query_store_query q ON p.query_id = q.query_id
JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id
GROUP BY qt.query_text_id, q.query_id, p.plan_id
ORDER BY sum_total_wait_ms DESC
;WITH MyDuplicate AS (SELECT
Sch.[name] AS SchemaName,
Obj.[name] AS TableName,
Idx.[name] AS IndexName,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 1) AS Col1,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 2) AS Col2,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 3) AS Col3,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 4) AS Col4,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 5) AS Col5,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 6) AS Col6,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 7) AS Col7,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 8) AS Col8,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 9) AS Col9,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 10) AS Col10,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 11) AS Col11,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 12) AS Col12,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 13) AS Col13,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 14) AS Col14,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 15) AS Col15,
INDEX_COL(Sch.[name] + '.' + Obj.[name], Idx.index_id, 16) AS Col16
FROM sys.indexes Idx
INNER JOIN sys.objects Obj ON Idx.[object_id] = Obj.[object_id] INNER JOIN sys.schemas Sch ON Sch.[schema_id] = Obj.[schema_id] WHERE index_id > 0)
SELECT MD1.SchemaName, MD1.TableName, MD1.IndexName,
MD2.IndexName AS OverLappingIndex,
MD1.Col1, MD1.Col2, MD1.Col3, MD1.Col4,
MD1.Col5, MD1.Col6, MD1.Col7, MD1.Col8,
MD1.Col9, MD1.Col10, MD1.Col11, MD1.Col12,
MD1.Col13, MD1.Col14, MD1.Col15, MD1.Col16
FROM MyDuplicate MD1
INNER JOIN MyDuplicate MD2 ON MD1.tablename = MD2.tablename
AND MD1.indexname <> MD2.indexname
AND MD1.Col1 = MD2.Col1
AND (MD1.Col2 IS NULL OR MD2.Col2 IS NULL OR MD1.Col2 = MD2.Col2)
AND (MD1.Col3 IS NULL OR MD2.Col3 IS NULL OR MD1.Col3 = MD2.Col3)
AND (MD1.Col4 IS NULL OR MD2.Col4 IS NULL OR MD1.Col4 = MD2.Col4)
AND (MD1.Col5 IS NULL OR MD2.Col5 IS NULL OR MD1.Col5 = MD2.Col5)
AND (MD1.Col6 IS NULL OR MD2.Col6 IS NULL OR MD1.Col6 = MD2.Col6)
AND (MD1.Col7 IS NULL OR MD2.Col7 IS NULL OR MD1.Col7 = MD2.Col7)
AND (MD1.Col8 IS NULL OR MD2.Col8 IS NULL OR MD1.Col8 = MD2.Col8)
AND (MD1.Col9 IS NULL OR MD2.Col9 IS NULL OR MD1.Col9 = MD2.Col9)
AND (MD1.Col10 IS NULL OR MD2.Col10 IS NULL OR MD1.Col10 = MD2.Col10)
AND (MD1.Col11 IS NULL OR MD2.Col11 IS NULL OR MD1.Col11 = MD2.Col11)
AND (MD1.Col12 IS NULL OR MD2.Col12 IS NULL OR MD1.Col12 = MD2.Col12)
AND (MD1.Col13 IS NULL OR MD2.Col13 IS NULL OR MD1.Col13 = MD2.Col13)
AND (MD1.Col14 IS NULL OR MD2.Col14 IS NULL OR MD1.Col14 = MD2.Col14)
AND (MD1.Col15 IS NULL OR MD2.Col15 IS NULL OR MD1.Col15 = MD2.Col15)
AND (MD1.Col16 IS NULL OR MD2.Col16 IS NULL OR MD1.Col16 = MD2.Col16)
ORDER BY MD1.SchemaName,MD1.TableName,MD1.IndexName
-- 저장 프로시저, 트리거 및 사용자 정의 함수가 다음에 실행될 때 다시 컴파일되도록 합니다.
-- 프로시저나 트리거가 다음에 실행될 때 기존 계획을 프로시저 캐시에서 삭제하고 새 계획이 생성되도록 하여 이 작업을 수행합니다.
-- 서비스 도중 일반적이지 않은 조건의 데이터가 사용되어 생성된 실행 계획이 사용되어 성능 이슈가 발생하는 경우, 실행계획 초기화 및 다시 생성에 유용함.
USE AdventureWorks2012;
GO
EXEC sp_recompile N'Sales.Customer';
GO
-- MSSQL Error Log가 너무 많이 쌓였을때 유용함
-- 현재의 오류 로그 파일을 닫고 서버를 다시 시작하는 것처럼 오류 로그 확장 번호를 순환시킵니다.
-- 새 오류 로그는 버전, 저작권에 관한 정보 및 새 로그가 작성되었음을 표시하는 행을 포함합니다.
sp_cycle_errorlog